正则expression式匹配,排除时间… /除了之间
– 编辑 – 目前的答案有一些有用的想法,但我想要更完整的东西,我可以100%的理解和重用; 这就是为什么我设置赏金。 对于我来说,无处不在的想法也不是像\K这样的标准语法
这个问题是关于如何匹配一个模式,除了一些情况s1 s2 s3。 我给出了一个具体的例子来展示我的意思,但更喜欢一个普遍的答案,我可以100%的理解,所以我可以在其他情况下重用。
例
我想用\b\d{5}\b匹配五个数字,但是在三种情况下不能匹配s1 s2 s3:
s1:不在以这句话结束的句子中。
s2:没有在parens内的任何地方。
s3:不在以if(开头的块中if(并以//endif结尾
我知道如何用向前和向后的方式解决s1 s2 s3中的任何一个,特别是在C#lookbehind或PHP中的\K
例如
s1 (?m)(?!\d+.*?\.$)\d+
s3 with C#lookbehind (?<!if\(\D*(?=\d+.*?//endif))\b\d+\b
s3用PHP \ K (?:(?:if\(.*?//endif)\D*)*\K\d+
但条件的混合在一起使我的头部爆炸。 更坏的消息是,我可能需要另外添加其他条件s4 s5。
好消息是,我不在乎是否使用PHP,C#,Python或邻居的洗衣机等大多数常用语言来处理这些文件。 :)我几乎是Python和Java的初学者,但有兴趣了解它是否有解决scheme。
所以我来这里看看是否有人想到一个灵活的配方。
提示是好的:你不需要给我完整的代码。 🙂
谢谢。
汉斯,我会引用我早些时候的回答。 你说你想要“更完整的东西”,所以我希望你不会介意漫长的回答 – 只是想讨好。 我们从一些背景开始。
首先,这是一个很好的问题。 除了在某些情况下(例如,在代码块内或在括号内),经常会有关于匹配某些模式的问题。 这些问题通常会导致相当尴尬的解决scheme。 所以你关于多个上下文的问题是一个特殊的挑战。
惊
令人惊讶的是,至less有一个有效的解决scheme是一般的,易于实施和维护的乐趣。 它适用于所有正则expression式 ,允许您检查代码中的捕获组。 它恰好回答了一些常见的问题,可能起初听起来不同于你的:“除了甜甜圈以外的所有东西”,“replace除了…之外的所有东西”,“匹配除了我妈妈的黑名单上的所有单词”,“忽略标签“,”匹配温度,除非斜体“…
可悲的是,这种技术并不为人所知,我估计在二十个可以使用它的问题中,只有一个答案提到了这个问题 – 也就是说五十到六十个答案中的一个。 在评论中看到我与Kobi的交stream。 这个技术在本文中有一些深度的描述,它把它(乐观的)称为“有史以来最好的正则expression式”。 没有深入细节,我会尽力让你牢牢掌握技术的运作方式。 有关各种语言的更多详细信息和代码示例,我鼓励您查阅该资源。
一个更好的已知变化
使用Perl和PHP特有的语法有一个变化,即完成相同的操作。 你会看到它在正义大师,如CasimiretHippolyte和HamZa手中 。 我将在下面告诉你更多关于这方面的内容,但是我的重点在于可以与所有正则expression式一起工作的通用解决scheme(只要你可以在代码中检查捕获组)。
感谢所有的背景,zx81 …但是什么是配方?
关键事实
该方法返回组1捕获中的匹配。 它根本不关心整体比赛。
事实上, 诀窍在于匹配我们不想要的各种上下文 (使用| OR / alternation来链接这些上下文) 以“中和它们”。 在匹配所有不需要的上下文之后,交替的最后部分匹配我们想要的并将其捕获到组1。
一般的配方是
Not_this_context|Not_this_either|StayAway|(WhatYouWant)
这将匹配Not_this_context ,但从某种意义上说,匹配会进入垃圾箱,因为我们不会看整体匹配:我们只看第1组捕获。
在你的情况下,你的数字和三个上下文都可以忽略,我们可以这样做:
s1|s2|s3|(\b\d+\b)
请注意,因为我们实际上匹配s1,s2和s3,而不是试图避免它们周围的查找,s1,s2和s3的个别expression式可以保持清晰。 (它们是|每一边的子expression式)
整个expression式可以这样写:
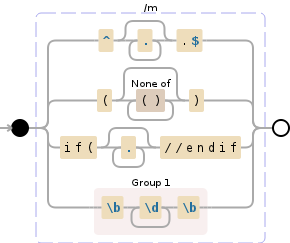
(?m)^.*\.$|\([^\)]*\)|if\(.*?//endif|(\b\d+\b)
看到这个演示 (但关注右下方窗格中的捕获组)。
如果你精神上试图在每个|分割这个正则expression式 定界符,它实际上只是一系列四个非常简单的expression式。
对于支持自由间距的口味来说,这个读法特别好。
(?mx) ### s1: Match line that ends with a period ### ^.*\.$ | ### OR s2: Match anything between parentheses ### \([^\)]*\) | ### OR s3: Match any if(...//endif block ### if\(.*?//endif | ### OR capture digits to Group 1 ### (\b\d+\b)
这是非常容易阅读和维护。
扩展正则expression式
当你想忽略更多的情况s4和s5,你可以在左边添加更多的变化:
s4|s5|s1|s2|s3|(\b\d+\b)
这个怎么用?
你不想要的上下文被添加到左边的变更列表中:它们将匹配,但是这些整体匹配从不被检查,所以匹配它们是将它们放入“垃圾箱”中的一种方式。
然而,您想要的内容被捕获到组1.然后,您必须以编程方式检查组1是否设置为空。 这是一个微不足道的编程任务(我们稍后会讨论它是如何完成的),特别是考虑到它给你一个简单的正则expression式,你可以一目了然地理解并根据需要修改或扩展。
我并不总是一个可视化的粉丝,但是这个方法很好的展示了这个方法的简单性。 每条“线”对应于潜在的匹配,但是只有底线被捕获到组1中。
Debuggex演示
Perl / PCRE变化
与上面的通用解决scheme相反,在SO上经常出现Perl和PCRE的变化,至less在正则expression式的诸如@CasimiretHippolyte和@HamZa之类的手中。 它是:
(?:s1|s2|s3)(*SKIP)(*F)|whatYouWant
在你的情况下:
(?m)(?:^.*\.$|\([^()]*\)|if\(.*?//endif)(*SKIP)(*F)|\b\d+\b
这个变体比较容易使用,因为在上下文s1,s2和s3中匹配的内容被简单地跳过了,所以你不需要检查组1的捕获(注意圆括号不见了)。 比赛只包含你whatYouWant
请注意(*F) , (*FAIL)和(?!)都是一样的东西。 如果你想变得更加模糊,你可以使用(*SKIP)(?!)
演示这个版本
应用
这里有一些常见的问题,这种技术可以经常轻松解决。 你会注意到,单词select可以使这些问题听起来不同,而实际上它们几乎是相同的。
- 除了像
<a stuff...>...</a>类的标签中的任何地方,我如何匹配foo? - 除了
<i>标签或javascript代码片段(更多条件),我如何匹配foo? - 我怎样才能匹配不在这个黑名单上的所有单词?
- 如何忽略SUB … END SUB块内的任何内容?
- 我怎么能匹配除了… s1 s2 s3之外的所有东西?
如何编程组1捕获
你没有代码,但为了完成…检查组1的代码显然取决于你select的语言。 无论如何,它不应该添加更多的代码来检查匹配的代码。
如果有疑问,我build议你看看前面提到的文章中的代码示例部分 ,它提供了很多种语言的代码。
备择scheme
根据问题的复杂性以及使用的正则expression式引擎,有几种select。 以下是适用于大多数情况的两种情况,包括多种情况。 在我看来,如果仅仅是因为清晰度总是胜出,那么它们几乎都不像s1|s2|s3|(whatYouWant)配方那么有吸引力。
1.replace然后匹配。
一个很好的解决scheme听起来很拙劣,但在很多环境下运行良好,需要分两步进行。 第一个正则expression式通过replace可能有冲突的string来中和要忽略的上下文。 如果只想匹配,则可以用空stringreplace,然后在第二步中运行匹配。 如果你想replace,你可以先用一些特殊的东西来replace被忽略的string,例如用一个固定宽度的@@@链来包围你的数字。 replace之后,你可以自由地取代你真正想要的东西,那么你将不得不恢复你独特的@@@string。
2.看看。
您原来的post表明您了解如何使用lookarounds排除单个条件。 你说C#对此很好,而且你是对的,但它不是唯一的select。 在C#,VB.NET和Visual C ++中find的.NET正则expression式风格,以及在Python中replacere的仍然是实验的regex模块,是我所知道的唯一支持无限宽度后视的两个引擎。 有了这些工具,在一个向后看的情况下,一个条件可以照顾不仅看在后面,而且在比赛和超越比赛,避免需要与前瞻的协调。 更多的条件? 更多的观点。
回收你在C#中使用s3的正则expression式,整个模式看起来就像这样。
(?!.*\.)(?<!\([^()]*(?=\d+[^)]*\)))(?<!if\(\D*(?=\d+.*?//endif))\b\d+\b
但现在你知道我不推荐这个,对吧?
缺失
@HamZa和@Jerrybuild议我提到一个额外的伎俩,当你试图删除WhatYouWant 。 你记得配合WhatYouWant (将它捕获到组1中)的配方是s1|s2|s3|(WhatYouWant) ,对吗? 要删除WhatYouWant所有实例,请将该正则expression式更改为
(s1|s2|s3)|WhatYouWant
对于replacestring,您使用$1 。 这里发生的是,对于匹配的每个s1|s2|s3实例,replace$1将replace该实例(由$1引用)。 另一方面,当WhatYouWant被匹配时,它被一个空的组所替代,而没有其他的东西 – 因此被删除。 看到这个演示 ,谢谢@HamZa和@Jerrybuild议这个美好的加法。
更换
这带来了替代品,我将简要地介绍。
- 当没有replace时,请参阅上面的“删除”技巧。
- 当更换时,如果使用Perl或PCRE,使用上面提到的
(*SKIP)(*F)变体来完全匹配你想要的,并做一个直接replace。 - 在其他风格中,在replace函数调用中,使用callback函数或lambda检查匹配项,如果组1被设置则replace。 如果您需要这方面的帮助,那么已经引用的文章会给您提供各种语言的代码。
玩的开心!
不,等等,还有更多!
啊,不,我将把它存成二十卷的回忆录,在明年spring发行。
做三个不同的匹配,并使用in-program条件逻辑处理这三种情况的组合。 你不需要在一个巨大的正则expression式中处理所有事情。
编辑:让我扩大一点,因为这个问题变得更有趣了:-)
您在此尝试捕获的一般想法是匹配某个正则expression式模式,但是当testingstring中存在某些其他(可能是任意数量)模式时,则不会这样。 幸运的是,您可以利用您的编程语言:保持正则expression式简单,只需使用复合条件。 最好的做法是在可重用的组件中捕获这个想法,所以让我们创build一个实现它的类和方法:
using System.Collections.Generic; using System.Linq; using System.Text.RegularExpressions; public class MatcherWithExceptions { private string m_searchStr; private Regex m_searchRegex; private IEnumerable<Regex> m_exceptionRegexes; public string SearchString { get { return m_searchStr; } set { m_searchStr = value; m_searchRegex = new Regex(value); } } public string[] ExceptionStrings { set { m_exceptionRegexes = from es in value select new Regex(es); } } public bool IsMatch(string testStr) { return ( m_searchRegex.IsMatch(testStr) && !m_exceptionRegexes.Any(er => er.IsMatch(testStr)) ); } } public class App { public static void Main() { var mwe = new MatcherWithExceptions(); // Set up the matcher object. mwe.SearchString = @"\b\d{5}\b"; mwe.ExceptionStrings = new string[] { @"\.$" , @"\(.*" + mwe.SearchString + @".*\)" , @"if\(.*" + mwe.SearchString + @".*//endif" }; var testStrs = new string[] { "1." // False , "11111." // False , "(11111)" // False , "if(11111//endif" // False , "if(11111" // True , "11111" // True }; // Perform the tests. foreach (var ts in testStrs) { System.Console.WriteLine(mwe.IsMatch(ts)); } } }
因此,我们设置searchstring(五位数字),多个exceptionstring(您的s1 , s2和s3 ),然后尝试匹配几个testingstring。 打印结果应如每个testingstring旁边的注释中所示。
您的要求,它不是内部parens不可能满足所有情况。 也就是说,如果你能以某种方式find一个(左边)和右边,这并不总是意味着你在parens里面。 例如。
(....) + 55555 + (.....) – 不在里面parens还有(和)左右
现在你可能会觉得自己很聪明,而且只有在你没有遇到的时候才会去寻找(左边) ,反之亦然。 这不适用于这种情况:
((.....) + 55555 + (.....)) – 里面parens即使有closures)和(从左到右。
使用正则expression式不可能知道你是否在parens里,因为正则expression式不能计算已经打开了多less个parens以及closures了多less个parens。
考虑这个更简单的任务:使用正则expression式,找出是否所有(可能嵌套)在一个stringparens是closures的,这是每个(你需要find) 。 你会发现这是不可能解决的,如果你不能解决这个问题,那么你不能找出一个单词是否在所有情况下的parens,因为你不能找出一个位置的stringif全部在前(有相应的) 。
汉斯如果你不介意我用你的邻居的洗衣机叫perl 🙂
编辑:下面的伪代码:
loop through input if line contains 'if(' set skip=true if skip= true do nothing else if line match '\b\d{5}\b' set s0=true if line does not match s1 condition set s1=true if line does not match s2 condition set s2=true if s0,s1,s2 are true print line if line contains '//endif' set skip=false
鉴于文件input.txt:
tiago@dell:~$ cat input.txt this is a text it should match 12345 if( it should not match 12345 //endif it should match 12345 it should not match 12345. it should not match ( blabla 12345 blablabla ) it should not match ( 12345 ) it should match 12345
和脚本validator.pl:
tiago@dell:~$ cat validator.pl #! /usr/bin/perl use warnings; use strict; use Data::Dumper; sub validate_s0 { my $line = $_[0]; if ( $line =~ \d{5/ ){ return "true"; } return "false"; } sub validate_s1 { my $line = $_[0]; if ( $line =~ /\.$/ ){ return "false"; } return "true"; } sub validate_s2 { my $line = $_[0]; if ( $line =~ /.*?\(.*\d{5.*?\).*/ ){ return "false"; } return "true"; } my $skip = "false"; while (<>){ my $line = $_; if( $line =~ /if\(/ ){ $skip = "true"; } if ( $skip eq "false" ) { my $s0_status = validate_s0 "$line"; my $s1_status = validate_s1 "$line"; my $s2_status = validate_s2 "$line"; if ( $s0_status eq "true"){ if ( $s1_status eq "true"){ if ( $s2_status eq "true"){ print "$line"; } } } } if ( $line =~ /\/\/endif/) { $skip="false"; } }
执行:
tiago @ dell:〜$ cat input.txt | perl validator.pl 它应该匹配12345 它应该匹配12345 它应该匹配12345
不知道这是否会帮助你,但我提供了一个解决scheme,考虑以下假设 –
- 你需要一个优雅的解决scheme来检查所有的条件
- 条件可以在将来和随时改变。
- 一个条件不应该依赖于别人。
不过,我也考虑以下 –
- 给定的文件有最小的错误。 如果这样做,那么我的代码可能需要一些修改,以应付这种情况。
- 我用Stack来跟踪
if(块。
好的,这里是解决scheme –
我使用C#和MEF(Microsoft扩展框架)来实现可configuration的parsing器。 这个想法是,使用一个单一的分析器parsing和一个可configuration的validation器类的列表来validation线,并根据validation返回true或false。 然后,您可以随时添加或删除任何validation程序,也可以添加新的validation程序。 到目前为止,我已经为你提到的S1,S2和S3实现了,在第3点检查类。如果将来需要,你必须为s4,s5添加类。
-
首先,创build接口 –
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace FileParserDemo.Contracts { public interface IParser { String[] GetMatchedLines(String filename); } public interface IPatternMatcher { Boolean IsMatched(String line, Stack<string> stack); } } -
然后是文件阅读器和检查器 –
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using FileParserDemo.Contracts; using System.ComponentModel.Composition.Hosting; using System.ComponentModel.Composition; using System.IO; using System.Collections; namespace FileParserDemo.Parsers { public class Parser : IParser { [ImportMany] IEnumerable<Lazy<IPatternMatcher>> parsers; private CompositionContainer _container; public void ComposeParts() { var catalog = new AggregateCatalog(); catalog.Catalogs.Add(new AssemblyCatalog(typeof(IParser).Assembly)); _container = new CompositionContainer(catalog); try { this._container.ComposeParts(this); } catch { } } public String[] GetMatchedLines(String filename) { var matched = new List<String>(); var stack = new Stack<string>(); using (StreamReader sr = File.OpenText(filename)) { String line = ""; while (!sr.EndOfStream) { line = sr.ReadLine(); var m = true; foreach(var matcher in this.parsers){ m = m && matcher.Value.IsMatched(line, stack); } if (m) { matched.Add(line); } } } return matched.ToArray(); } } } -
然后是个别跳棋的实现,类名是自我解释的,所以我不认为他们需要更多的描述。
using FileParserDemo.Contracts; using System; using System.Collections.Generic; using System.ComponentModel.Composition; using System.Linq; using System.Text; using System.Text.RegularExpressions; using System.Threading.Tasks; namespace FileParserDemo.PatternMatchers { [Export(typeof(IPatternMatcher))] public class MatchAllNumbers : IPatternMatcher { public Boolean IsMatched(String line, Stack<string> stack) { var regex = new Regex("\\d+"); return regex.IsMatch(line); } } [Export(typeof(IPatternMatcher))] public class RemoveIfBlock : IPatternMatcher { public Boolean IsMatched(String line, Stack<string> stack) { var regex = new Regex("if\\("); if (regex.IsMatch(line)) { foreach (var m in regex.Matches(line)) { //push the if stack.Push(m.ToString()); } //ignore current line, and will validate on next line with stack return true; } regex = new Regex("//endif"); if (regex.IsMatch(line)) { foreach (var m in regex.Matches(line)) { stack.Pop(); } } return stack.Count == 0; //if stack has an item then ignoring this block } } [Export(typeof(IPatternMatcher))] public class RemoveWithEndPeriod : IPatternMatcher { public Boolean IsMatched(String line, Stack<string> stack) { var regex = new Regex("(?m)(?!\\d+.*?\\.$)\\d+"); return regex.IsMatch(line); } } [Export(typeof(IPatternMatcher))] public class RemoveWithInParenthesis : IPatternMatcher { public Boolean IsMatched(String line, Stack<string> stack) { var regex = new Regex("\\(.*\\d+.*\\)"); return !regex.IsMatch(line); } } } -
该程序 –
using FileParserDemo.Contracts; using FileParserDemo.Parsers; using System; using System.Collections.Generic; using System.ComponentModel.Composition; using System.IO; using System.Linq; using System.Text; using System.Threading.Tasks; namespace FileParserDemo { class Program { static void Main(string[] args) { var parser = new Parser(); parser.ComposeParts(); var matches = parser.GetMatchedLines(Path.GetFullPath("test.txt")); foreach (var s in matches) { Console.WriteLine(s); } Console.ReadLine(); } } }
为了testing,我把@ Tiago的示例文件作为Test.txt ,它有以下几行 –
this is a text it should match 12345 if( it should not match 12345 //endif it should match 12345 it should not match 12345. it should not match ( blabla 12345 blablabla ) it should not match ( 12345 ) it should match 12345
给出输出 –
it should match 12345 it should match 12345 it should match 12345
不知道这是否会帮助你,我确实有一个有趣的时间玩它:)
与它最好的部分是,添加一个新的条件,所有你需要做的是提供一个IPatternMatcher的实现,它会自动被调用,从而将validation。
与@ zx81的(*SKIP)(*F)但是使用负向前瞻断言。
(?m)(?:if\(.*?\/\/endif|\([^()]*\))(*SKIP)(*F)|\b\d+\b(?!.*\.$)
DEMO
在Python中,我会这样做,
import re string = """cat 123 sat. I like 000 not (456) though 111 is fine 222 if( //endif if(cat==789 stuff //endif 333""" for line in string.split('\n'): # Split the input according to the `\n` character and then iterate over the parts. if not line.endswith('.'): # Don't consider the part which ends with a dot. for i in re.split(r'\([^()]*\)|if\(.*?//endif', line): # Again split the part by brackets or if condition which endswith `//endif` and then iterate over the inner parts. for j in re.findall(r'\b\d+\b', i): # Then find all the numbers which are present inside the inner parts and then loop through the fetched numbers. print(j) # Prints the number one ny one.
输出:
000 111 222 333
