使用常数整数除法器进行高效的浮点除法
最近的一个问题 ,是不是允许编译器用浮点乘法来取代浮点运算,这就激励我提出这个问题。
在严格的要求下,代码转换后的结果应该与实际的除法运算按位相同,但对于二进制IEEE-754algorithm来说,对于二的幂因子是可能的。 只要除数的倒数是可以代表的,乘以除数的倒数即可得出与该除数相同的结果。 例如,乘以0.5可以代替2.0 。
然后人们想知道这样的replace是如何工作的,假设我们允许任何简短的指令序列来代替除法,但运行速度明显更快,同时提供相同的结果。 除了普通的乘法之外,还特别允许融合的乘加运算。 我在评论中指出了以下相关文章:
Nicolas Brisebarre,Jean-Michel Muller和Saurabh Kumar Raina。 提前知道除数时加速正确舍入的浮点除法。 IEEE Transactions on Computers,Vol。 53,第8号,2004年8月,第1069-1072页。
本文作者所提倡的技术将计算除数y的倒数作为归一化的头尾对z h :z l如下: z h = 1 / y,z l = fma(-y,z h ,1 )/ y 。 之后,分割q = x / y然后被计算为q = fma(z h ,x,z l * x) 。 本文导出了除数y必须满足的各种条件才能使该algorithm正常工作。 正如人们容易观察到的那样,当头部和尾部的符号不同时,该algorithm存在无穷大和零的问题。 更重要的是,由于商尾zl * x的计算遭受下溢,所以它将不能提供非常小的股息x的正确结果。
本文还提供了另一种基于FMA的分割algorithm,由Peter Markstein在IBM任职时开创。 相关的参考资料是:
PW Markstein。 计算IBM RISC System / 6000处理器上的基本function。 IBM研究与发展杂志,Vol。 34,No.1,1990年1月,第111-119页
在Marksteinalgorithm中,首先计算一个倒数rc ,由此形成初始商q = x * rc 。 然后,用FMA精确计算除法的余数为r = fma(-y,q,x) ,最终计算出一个改进的更精确的商,即q = fma(r,rc,q) 。
这个algorithm对x也是有问题的,它们是零或者无穷(可以很容易的用适当的条件执行来解决),但是使用IEEE-754单精度float数据的详尽的testing表明它为所有可能的分红x提供了许多因数的正确商,在这许多小的整数之中。 这个C代码实现它:
/* precompute reciprocal */ rc = 1.0f / y; /* compute quotient q=x/y */ q = x * rc; if ((x != 0) && (!isinf(x))) { r = fmaf (-y, q, x); q = fmaf (r, rc, q); }
在大多数处理器体系结构中,这应该转换成无分支指令序列,使用预测,条件移动或selecttypes指令。 举一个具体的例子:对于除以3.0f ,CUDA 7.5的nvcc编译器为Kepler-class GPU生成以下机器代码:
LDG.E R5, [R2]; // load x FSETP.NEU.AND P0, PT, |R5|, +INF , PT; // pred0 = fabsf(x) != INF FMUL32I R2, R5, 0.3333333432674408; // q = x * (1.0f/3.0f) FSETP.NEU.AND P0, PT, R5, RZ, P0; // pred0 = (x != 0.0f) && (fabsf(x) != INF) FMA R5, R2, -3, R5; // r = fmaf (q, -3.0f, x); MOV R4, R2 // q @P0 FFMA R4, R5, c[0x2][0x0], R2; // if (pred0) q = fmaf (r, (1.0f/3.0f), q) ST.E [R6], R4; // store q
对于我的实验,我写了如下所示的微小的Ctesting程序,按递增顺序通过整数除数,并且对每个程序都进行了彻底的testing,以对照正确的划分对上述代码序列进行testing。 它打印一个通过这个穷举testing的除数列表。 部分输出如下所示:
PASS: 1, 2, 3, 4, 5, 7, 8, 9, 11, 13, 15, 16, 17, 19, 21, 23, 25, 27, 29, 31, 32, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 64, 65, 67, 69,
为了将replacealgorithm结合到编译器中作为优化,可以安全地应用上述代码变换的除数的白名单是不切实际的。 到目前为止,程序的输出(以每分钟大约一个结果的速率)表明,对于那些奇数整数或二的幂的因子,快速代码在x所有可能的编码中正确地工作。 轶事证据,当然不是certificate。
什么样的math条件可以事先确定划分到上述代码序列的转换是否安全? 答案可以假定所有的浮点运算都是以“round to nearest or even”的默认舍入模式执行的。
#include <stdlib.h> #include <stdio.h> #include <math.h> int main (void) { float r, q, x, y, rc; volatile union { float f; unsigned int i; } arg, res, ref; int err; y = 1.0f; printf ("PASS: "); while (1) { /* precompute reciprocal */ rc = 1.0f / y; arg.i = 0x80000000; err = 0; do { /* do the division, fast */ x = arg.f; q = x * rc; if ((x != 0) && (!isinf(x))) { r = fmaf (-y, q, x); q = fmaf (r, rc, q); } res.f = q; /* compute the reference, slowly */ ref.f = x / y; if (res.i != ref.i) { err = 1; break; } arg.i--; } while (arg.i != 0x80000000); if (!err) printf ("%g, ", y); y += 1.0f; } return EXIT_SUCCESS; }
让我第三次重新启动。 我们正在努力加速
q = x / y
其中y是一个整数常量, q , x和y都是IEEE 754-2008 binary32浮点值。 在下面, fmaf(a,b,c)表示使用binary32值的一个融合的乘加a * b + c 。
天真的algorithm是通过预先计算的倒数,
C = 1.0f / y
所以在运行时(一个更快)的乘法就足够了:
q = x * C
Brisebarre-Muller-Raina加速度使用两个预先计算的常量,
zh = 1.0f / y zl = -fmaf(zh, y, -1.0f) / y
所以在运行时,一个乘法和一个融合的乘加就足够了:
q = fmaf(x, zh, x * zl)
Marksteinalgorithm将天真的方法与两个融合的乘法相结合,如果初始方法在最不重要的地方产生一个单位内的结果,则通过预先计算得出正确的结果
C1 = 1.0f / y C2 = -y
这样可以近似使用divison
t1 = x * C1 t2 = fmaf(C1, t1, x) q = fmaf(C2, t2, t1)
天真的方法适用于所有的两个权力,但否则它是非常糟糕的。 例如,对于除数7,14,15,28和30,对于所有可能x一半以上,它会产生不正确的结果。
Brisebarre-Muller-Raina方法对于两个y几乎所有非功率也类似地失败,但是less得多的x产生不正确的结果(小于所有可能的x的百分之五,取决于y )。
Brisebarre-Muller-Raina文章显示,天真方法中的最大误差是±1.5 ULP。
Markstein方法对于两个y幂,对于奇数y也产生正确的结果。 (我还没有findMarkstein方法的失败奇数整数除数。)
对于Markstein方法,我已经分析了除数1 – 19700( 原始数据在这里 )。
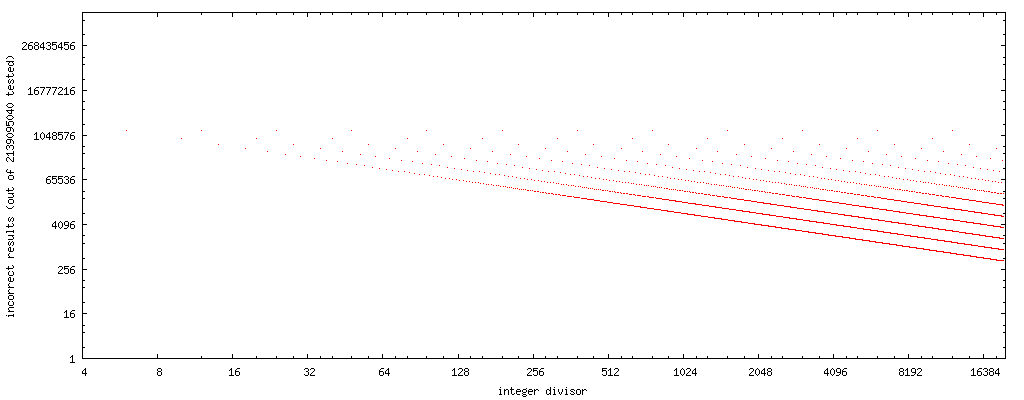
绘制失败案例的数量(水平轴上的除数,对于所述除数,Markstein方法失效的x的数值),我们可以看到一个简单的模式:
马克斯坦失败案例answers/markstein.png
请注意,这些图表的水平轴和垂直轴都是对数的。 奇数除数是没有点的,因为这个方法对于我testing的所有奇数除数都能得到正确的结果。
如果我们把x轴改成反转位(反转的二进制数字,即0b11101101→0b10110111, 数据 )的除数,我们有一个非常清晰的模式: Markstein故障情况,位反向除数http://www.nominal- animal.net/answers/markstein-failures.png
如果我们通过点集的中心绘制一条直线,我们得到曲线4194304/x 。 (记住,情节只考虑一半可能的花车,所以当考虑所有可能的花车时,将其加倍。) 8388608/x和2097152/x完全包含整个错误模式。
因此,如果我们使用rev(y)计算除数y的位反转,那么8388608/rev(y)是Markstein方法产生不正确情况的情况数(在所有可能的float中)的一个好的一阶近似值导致一个平均的,非二次除数的除数y 。 (或者,上限为16777216/rev(x) 。)
增加了2016-02-28:给出了任何整数(二进制32)除数,我发现使用Markstein方法的错误情况的近似值。 这里是伪代码:
function markstein_failure_estimate(divisor): if (divisor is zero) return no estimate if (divisor is not an integer) return no estimate if (divisor is negative) negate divisor # Consider, for avoiding underflow cases, if (divisor is very large, say 1e+30 or larger) return no estimate - do as division while (divisor > 16777216) divisor = divisor / 2 if (divisor is a power of two) return 0 if (divisor is odd) return 0 while (divisor is not odd) divisor = divisor / 2 # Use return (1 + 83833608 / divisor) / 2 # if only nonnegative finite float divisors are counted! return 1 + 8388608 / divisor
在我testing的Markstein故障情况下(但我还没有充分testing大于8388608的除数),这产生了一个正确的误差估计,误差在±1以内。 最后的划分应该是这样的,它报告没有虚假的零,但我不能保证(还)。 它没有考虑到非常大的因子(比如说0x1p100,或者1e + 30,以及更大的数量级),这些因素都有下溢的问题 – 无论如何,我肯定会排除这样的因数。
在初步testing中,这个估计似乎是非常准确的。 我没有画一个比较估计值和因子1到20000的实际误差的情节,因为所有的点都完全相同。 (在这个范围内,估计是准确的,或者是一个太大。)本质上,估计重现了这个答案中的第一个图。
Markstein方法的失败模式是规则的,非常有趣。 该方法适用于两个因子的所有权力,以及所有的奇数整除因子。
对于大于16777216的除数,我始终如一地看到与除数除以2的最小次方产生小于16777216的值相同的错误。例如,0x1.3cdfa4p + 23和0x1.3cdfa4p + 41,0×1。 d8874p + 23和0x1.d8874p + 32,0×1.cf84f8p + 23和0x1.cf84f8p + 34,0×1.e4a7fp + 23和0x1.e4a7fp + 37。 (在每一对中,尾数是一样的,只有两个的幂是变化的。)
假设我的testing平台没有错误,这意味着Markstein方法也可以使用大于16777216的除数(数值小于1e + 30),如果除数除以2的最小次幂产量小于16777216的商,商数很奇怪。
这个问题要求提供一种方法来确定常数Y的值,这使得将x / Y转换为更便宜的使用FMA计算所有可能的x值的计算是安全的。 另一种方法是使用静态分析来确定x可以采取的值的过度近似,从而可以应用通常不稳定的转换,即知道转换后的代码与原始分割不同的值不会发生。
使用适合于浮点计算问题的浮点值集合的表示,即使是从函数开始的前向分析,也可以产生有用的信息。 例如:
float f(float z) { float x = 1.0f + z; float r = x / Y; return r; }
假设默认的四舍五入模式(*),在上面的函数中, x只能是NaN(如果input是NaN),+ 0.0f,或者一个大于2 -24的数字,而不是-0.0f或比2-24更接近零的任何东西。 这certificate了对于常数Y许多值,转换成问题所示的两种forms之一。
(*)的假设,没有它,许多优化是不可能的,并且C编译器已经创build,除非程序明确使用#pragma STDC FENV_ACCESS ON
转发静态分析,预测上面的x的信息可以基于一组expression式可以作为一个元组的浮点值的表示:
- 一组可能的NaN值的表示(由于NaN的行为是低标准的,所以select只使用一个布尔值,
true意思是一些NaN可以存在,而false表示不存在NaN) - 四个布尔标志分别指示+ inf,-inf,+0.0,-0.0,
- 负有限浮点值的包含区间,以及
- 正有限浮点值的包含区间。
为了遵循这种方法,静态分析器必须了解C程序中可能出现的所有浮点运算。 为了说明,在分析的代码中用于处理+的值U和V的集合之间的相加可以被实现为:
- 如果NaN出现在其中一个操作数中,或者如果操作数可以是相反符号的无穷大,则NaN出现在结果中。
- 如果0不能是U的值和V的结果,则使用标准间隔算术。 对于U的最大值和V中的最大值的轮到最近的加法获得结果的上限,因此这些边界应该以最近的圆来计算。
- 如果0可以是U的正值和V的负值相加的结果,则令M为U中的最小正值,使得-M存在于V中。
- 如果succ(M)存在于U中,那么这个值对结果的正值贡献succ(M)-M。
- 如果-succ(M)存在于V中,则这一对值将负值M-succ(M)贡献给结果的负值。
- 如果pred(M)存在于U中,则这一对值将负值pred(M)-M贡献给结果的负值。
- 如果-pred(M)存在于V中,那么这个值对结果的正值贡献值M-pred(M)。
- 如果0可以是加上U的负值和V的正值的结果,则做相同的工作。
致谢:以上借鉴了“改善浮点加法和减法约束”的思想,Bruno Marre&Claude Michel
例如:编译下面的函数f :
float f(float z, float t) { float x = 1.0f + z; if (x + t == 0.0f) { float r = x / 6.0f; return r; } return 0.0f; }
这个问题的方法拒绝把函数f分解转换成另一种forms,因为6不是可以无条件地转换分解的价值之一。 相反,我所build议的是从函数的开始开始应用一个简单的值分析,在这种情况下,确定x是+0.0f或至less2 -24的有限浮点数,并且使用这个信息来应用Brisebarre等人的转变,对x * C2不下溢的知识充满信心。
为了明确起见,我build议使用如下的algorithm来决定是否将分割转换为简单的分割:
-
Y是根据他们的algorithm使用Brisebarre等人的方法可以转化的价值之一吗? - 从他们的方法中,C1和C2有相同的符号,还是有可能排除红利是无限的可能性?
- 他们的方法C1和C2是否有相同的符号,或者
x只能取0的两个表示之一? 如果在C1和C2有不同符号的情况下,x只能是0的一个表示forms,请记住用FMA计算的符号来摆弄(**),使x在零时产生正确的零点。 - 能否保证股利的大小足以排除
x * C2下溢的可能性?
如果对这四个问题的答案是“是”,那么在编译函数的情况下,可以将该部分转换成乘法和FMA。 上述静态分析用于回答问题2,3和4。
(**)“摆弄符号”是指在必要时使用-FMA(-C1,x,(-C2)* x)代替FMA(C1,x,C2 * x)正确的时候,x只能是两个有符号的零之一
浮点除法的结果是:
- 一个标志标志
- 一个有效数字
- 一个指数
- 一组标志(溢出,下溢,不精确等 – 见
fenv())
获得前3个部分是正确的(但标志集不正确)是不够的。 没有进一步的知识(例如结果的哪一部分哪一部分实际上是重要的,股息的可能值等),我会假设用常数(和/或复杂的FMA混乱)乘以常数代替除法是几乎从来不安全。
此外; 对于现代的CPU,我也不会认为用2个FMAreplace一个分区总是一个改进。 例如,如果瓶颈是取指令/解码,那么这个“优化”会使性能变差。 又如,如果后续指令不依赖于结果(在等待结果的同时CPU可以并行执行许多其他指令),则FMA版本可能会引入多个依赖性延迟,从而使性能变差。 对于第三个例子,如果所有寄存器都被使用,那么FMA版本(需要额外的“实时”variables)可能会增加“溢出”并使性能变差。
注意(在许多情况下,但不是全部情况下)除以2的常数倍数的分割或乘法可以通过单独添加(具体地,向指数添加移位计数)来完成。
我喜欢@Pascal的答案,但是在优化中,最好是有一个简单的,被很好理解的转换子集,而不是一个完美的解决scheme。
所有当前和常见的历史浮点格式有一个共同点:二进制尾数。
因此,所有的分数都是有理数的forms:
x / 2 n
这与程序中的常量(以及所有可能的基数为10的分数)形成鲜明对比,这些常数是以下forms的有理数:
x /(2 n * 5 m )
因此,一个优化可以简单地testinginput和m == 0的倒数,因为这些数字完全以FP格式表示,并且与它们的操作应该产生在格式内精确的数字。
因此,例如,在.01至0.99的(十进制2位)范围内,除以下数字将被优化:
.25 .50 .75
而其他一切都不会。 (我想,先试一下,哈哈。)

{kind=link}