高质量,简单的随机密码生成器
我有兴趣创build一个非常简单,高(密码)质量的随机密码生成器。 有一个更好的方法吗?
import os, random, string length = 13 chars = string.ascii_letters + string.digits + '!@#$%^&*()' random.seed = (os.urandom(1024)) print ''.join(random.choice(chars) for i in range(length)) 密码困难的事情是让他们足够强大,仍然能够记住他们。 如果密码不是要被人记住的话,那密码就不是真的了。
你使用Python的os.urandom() :这很好。 对于任何实际的目的(甚至密码学), os.urandom()的输出与真实的alea是无法区分的。 然后你把它作为种子random ,这是不太好的:它是一个非encryption的PRNG,它的输出可能performance出某种结构,它不会在统计测量工具中注册,但可能被智能攻击者利用。 你应该一直使用os.urandom() 。 为了简单起见,请select长度为64的字母,例如字母(大写和小写),数字和两个额外的标点符号(如“+”和“/”)。 然后,对于每个密码字符,从os.urandom()获取一个字节,将模值64(这是无偏的,因为64除256)减less,并将结果用作chars数组中的索引。
用一个长度为64的字母表,每个字符可以得到6位熵(因为2 6 = 64)。 因此,13个字符,你得到78位的熵。 这在所有情况下都不是最终强大的,但是已经非常强大了(可以用几个月和几十亿美元计算的预算来击败,而不仅仅是数百万美元)。
XKCD有一个很好的解释,为什么你认为强密码不是 。
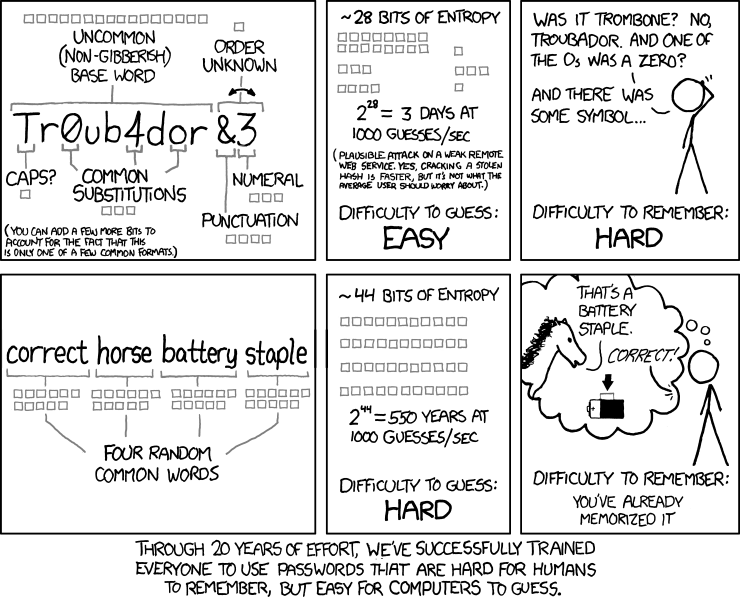
对于了解信息理论和安全的人,对于不和(不太可能涉及混合情况)的人发生激烈的争论,我诚恳地道歉。 – 兰德尔芒罗
如果你不明白这个插图说明背后的math问题 ,不要试图编写任何应该保密的东西,因为它不会。 只要把鼠标放下,离开键盘。
就在两天前,Kragen Javier Sitaker在http://lists.canonical.org/pipermail/kragen-hacks/2011-September/000527.html发布了一个程序来做这件事(现在走了; – 试试https://github.com / jesterpm / bin / blob / master / mkpasswd )
生成一个随机的,可存储的密码: http : //xkcd.com/936/
示例运行:
kragen at untorable:〜/ devel / inexorable-misc $ ./mkpass.py 5 12你的密码是“学习到的伤害保存住宅阶段”。 这相当于一个60位的密钥。
假设离线攻击一个MS-Cache哈希,这是最常用的密码哈希algorithm,比简单的MD5稍差一点,那么这个密码将花费2.5e + 03个CPU年来从我2008年便宜的Celeron E1200上破解。
目前最常用的密码散列algorithm是FreeBSD的迭代MD5; 破解这样的哈希将需要5.2e + 06 CPU年。
但是现代GPU可以快250倍,所以相同的迭代MD5将会在2e + 04 GPU-year。
2011年GPU每天的运行费用约为1.45美元,因此破解密码的成本大约是3美元+09美元。
我已经开始使用这种方式生成的密码来代替9个可打印的ASCII字符的随机密码,这个密码同样强大。 门罗的断言,这些密码更容易记住是正确的。 但是,仍然存在一个问题:由于每个字符的熵比特数较less(约1.7而不是6.6),密码中存在大量冗余,所以诸如ssh定时通道攻击(Song, Wagner和Tian草食动物的袭击,这是我早些时候在早些时候在巴格达咖啡馆的Bram Cohen所了解到的)和键盘录音攻击有更好的机会获得足够的信息,使密码可以攻击。
我的对抗草食动物攻击的方法是使用9个字符的密码,但对于我的新密码非常恼人,就是在字符之间input一个半秒的密码,以便定时通道不会带有太多关于实际使用的字符。 此外,9字符密码的较低长度固有地赋予了草食动物的方法更less的信息咀嚼。
其他可能的对策包括使用Emacs shell模式,它会在识别出密码提示时在本地提示您input密码,然后立即发送整个密码,并从其他地方复制并粘贴密码。
正如你所期望的那样,这个密码也需要一点时间才能input:约6秒而不是约3秒。
#!/usr/bin/python # -*- coding: utf-8 -*- import random, itertools, os, sys def main(argv): try: nwords = int(argv[1]) except IndexError: return usage(argv[0]) try: nbits = int(argv[2]) except IndexError: nbits = 11 filename = os.path.join(os.environ['HOME'], 'devel', 'wordlist') wordlist = read_file(filename, nbits) if len(wordlist) != 2**nbits: sys.stderr.write("%r contains only %d words, not %d.\n" % (filename, len(wordlist), 2**nbits)) return 2 display_password(generate_password(nwords, wordlist), nwords, nbits) return 0 def usage(argv0): p = sys.stderr.write p("Usage: %s nwords [nbits]\n" % argv0) p("Generates a password of nwords words, each with nbits bits\n") p("of entropy, choosing words from the first entries in\n") p("$HOME/devel/wordlist, which should be in the same format as\n") p("<http://canonical.org/~kragen/sw/wordlist>, which is a text file\n") p("with one word per line, preceded by its frequency, most frequent\n") p("words first.\n") p("\nRecommended:\n") p(" %s 5 12\n" % argv0) p(" %s 6\n" % argv0) return 1 def read_file(filename, nbits): return [line.split()[1] for line in itertools.islice(open(filename), 2**nbits)] def generate_password(nwords, wordlist): choice = random.SystemRandom().choice return ' '.join(choice(wordlist) for ii in range(nwords)) def display_password(password, nwords, nbits): print 'Your password is "%s".' % password entropy = nwords * nbits print "That's equivalent to a %d-bit key." % entropy print # My Celeron E1200 # (<http://ark.intel.com/products/34440/Intel-Celeron-Processor-E1200-(512K-Cache-1_60-GHz-800-MHz-FSB)>) # was released on January 20, 2008. Running it in 32-bit mode, # john --test (<http://www.openwall.com/john/>) reports that it # can do 7303000 MD5 operations per second, but I'm pretty sure # that's a single-core number (I don't think John is # multithreaded) on a dual-core processor. t = years(entropy, 7303000 * 2) print "That password would take %.2g CPU-years to crack" % t print "on my inexpensive Celeron E1200 from 2008," print "assuming an offline attack on a MS-Cache hash," print "which is the worst password hashing algorithm in common use," print "slightly worse than even simple MD5." print t = years(entropy, 3539 * 2) print "The most common password-hashing algorithm these days is FreeBSD's" print "iterated MD5; cracking such a hash would take %.2g CPU-years." % t print # (As it happens, my own machines use Drepper's SHA-2-based # hashing algorithm that was developed to replace the one # mentioned above; I am assuming that it's at least as slow as the # MD5-crypt.) # <https://en.bitcoin.it/wiki/Mining_hardware_comparison> says a # Core 2 Duo U7600 can do 1.1 Mhash/s (of Bitcoin) at a 1.2GHz # clock with one thread. The Celeron in my machine that I # benchmarked is basically a Core 2 Duo with a smaller cache, so # I'm going to assume that it could probably do about 1.5Mhash/s. # All common password-hashing algorithms (the ones mentioned # above, the others implemented in John, and bcrypt, but not # scrypt) use very little memory and, I believe, should scale on # GPUs comparably to the SHA-256 used in Bitcoin. # The same mining-hardware comparison says a Radeon 5870 card can # do 393.46 Mhash/s for US$350. print "But a modern GPU can crack about 250 times as fast," print "so that same iterated MD5 would fall in %.1g GPU-years." % (t / 250) print # Suppose we depreciate the video card by Moore's law, # ie halving in value every 18 months. That's a loss of about # 0.13% in value every day; at US$350, that's about 44¢ per day, # or US$160 per GPU-year. If someone wanted your password as # quickly as possible, they could distribute the cracking job # across a network of millions of these cards. The cards # additionally use about 200 watts of power, which at 16¢/kWh # works out to 77¢ per day. If we assume an additional 20% # overhead, that's US$1.45/day or US$529/GPU-year. cost_per_day = 1.45 cost_per_crack = cost_per_day * 365 * t print "That GPU costs about US$%.2f per day to run in 2011," % cost_per_day print "so cracking the password would cost about US$%.1g." % cost_per_crack def years(entropy, crypts_per_second): return float(2**entropy) / crypts_per_second / 86400 / 365.2422 if __name__ == '__main__': sys.exit(main(sys.argv))
实施@Thomas Pornin解决scheme
import M2Crypto import string def random_password(length=10): chars = string.ascii_uppercase + string.digits + string.ascii_lowercase password = '' for i in range(length): password += chars[ord(M2Crypto.m2.rand_bytes(1)) % len(chars)] return password
XKCD方法的另一个实现:
#!/usr/bin/env python import random import re # apt-get install wbritish def randomWords(num, dictionary="/usr/share/dict/british-english"): r = random.SystemRandom() # ie preferably not pseudo-random f = open(dictionary, "r") count = 0 chosen = [] for i in range(num): chosen.append("") prog = re.compile("^[az]{5,9}$") # reasonable length, no proper nouns if(f): for word in f: if(prog.match(word)): for i in range(num): # generate all words in one pass thru file if(r.randint(0,count) == 0): chosen[i] = word.strip() count += 1 return(chosen) def genPassword(num=4): return(" ".join(randomWords(num))) if(__name__ == "__main__"): print genPassword()
示例输出:
$ ./randompassword.py affluent afford scarlets twines $ ./randompassword.py speedboat ellipse further staffer
我知道这个问题在2011年已经发布,但是对于2014年以后的这个问题,我有一件事情要说:阻止轮胎的重振。
在这些情况下,最好的select是search开源软件,例如,将search限制在github结果中。 到目前为止,我发现的最好的事情是:
考虑到你的评论,
我只需要能够生成比我脑中想到的密码更安全的密码。
似乎你想用你的程序来生成密码,而不是把它写成练习。 最好使用现有的实现,因为如果你犯了一个错误,输出可能会受到影响。 阅读随机数字生成器攻击 ; 尤其是在Debian公布的一个众所周知的RNG bug中暴露了人们的SSL私钥。
所以相反,考虑使用pwgen 。 它提供了几个选项,您应该根据您计划使用的密码来select。
import random r = random.SystemRandom() def generate_password(words, top=2000, k=4, numbers=None, characters=None, first_upper=True): """Return a random password based on a sorted word list.""" elements = r.sample(words[:top], k) if numbers: elements.insert(r.randint(1, len(elements)), r.choice(numbers)) if characters: elements.insert(r.randint(1, len(elements)), r.choice(characters)) if first_upper: elements[0] = elements[0].title() return ''.join(elements) if __name__ == '__main__': with open('./google-10000-english-usa.txt') as f: words = [w.strip() for w in f] print(generate_password(words, numbers='0123456789', characters='!@#$%'))
- 生成您可以记住的密码
- 使用
os.urandom() - 处理现实世界的规则,如添加数字,大写,字符。
当然可以改善,但这是我使用的。
生成密码时不能相信python的伪随机数生成器。 它不一定是密码随机的。 你是从os.urandom播种伪随机数发生器,这是一个很好的开始。 但是之后你依靠python的生成器。
random.SystemRandom()类将随机数从同一个来源作为随机数获得更好的select。 根据python的文档,应该是足够好的密码使用。 SystemRandom类为您提供了随机类的所有function,但您不必担心伪随机性。
使用random.SystemRandom的示例代码(用于Python 2.6):
import random, string length = 13 chars = string.ascii_letters + string.digits + '!@#$%^&*()' rnd = random.SystemRandom() print ''.join(rnd.choice(chars) for i in range(length))
注意:您的里程可能会有所不同 – Python文档说随机.SystemRandom的可用性因操作系统而异。
这种方式的作品。 这很好。 如果还有其他规则,例如排除词典中的单词,那么您可能也希望包含这些filter,但是随机生成一个带有该设置的词典单词的可能性非常小。
为手头的主题构build我自己的CLI答案(完整源代码位于以下URL):
http://0netenv.blogspot.com/2016/08/password-generator-with-argparse.html
用argparse写了一个密码生成器。 希望这可以帮助某人(build立一个密码生成器或使用argparse)!
无论哪种方式,这是很有趣的build立!
$ ./pwgen.py -h usage: pwgen.py [-h] [-c COUNT] [-a] [-l] [-n] [-s] [-u] [-p] Create a random password Special characters, numbers, UPPERCASE -"Oscar", and lowercase -"lima" to avoid confusion. Default options (no arguments): -c 16 -a Enjoy! --0NetEnv@gmail.com optional arguments: -h, --help show this help message and exit -c COUNT, --count COUNT password length -a, --all same as -l -n -s -u -l, --lower include lowercase characters -n, --number include 0-9 -s, --special include special characters -u, --upper include uppercase characters -p, --license print license and exit
代码如下:
#!/usr/bin/env python2 # -*- coding: utf-8 -*- license = """ # pwgen -- the pseudo-random password generator # # This software is distributed under the MIT license. # # The MIT License (MIT) # # Copyright (c) 2016 0NetEnv 0netenv@gmail.com # Permission is hereby granted, free of charge, to any # person obtaining a copy of this software and associated # documentation files (the "Software"), to deal in the # Software without restriction, including without # limitation the rights to use, copy, modify, merge, # publish, distribute, sublicense, and/or sell copies # of the Software, and to permit persons to whom the # Software is furnished to do so, subject to the following # conditions: # # The above copyright notice and this permission notice # shall be included in all copies or substantial portions # of the Software. # # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF # ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED # TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A # PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT # SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY # CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION # OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR # IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER # DEALINGS IN THE SOFTWARE. # # NOTE: # This software was tested on Slackware 14.2, Raspbian, & # Mac OS X 10.11 # """ import string import random import sys # first time using argparse library import argparse # wanted to change the formatting of the help menu a little bit, so used RawTextHelpFormatter directly from argparse import RawTextHelpFormatter typo = '' c = 16 counter = 0 line = '-' * 40 # CREATE FUNCTION for PWGEN def pwgen(z, t): # EMPTY SET OF CHARACTERS charsset = '' # UPPERCASE -"O" U = 'ABCDEFGHIJKLMNPQRSTUVWXYZ' # lowercase -"l" L = 'abcdefghijkmnopqrstuvwxyz' N = '0123456789' S = '!@#$%^&*?<>' # make sure we're using an integer, not a char/string z = int(z) for type in t: if 'u' in t: charsset = charsset + U if 'l' in t: charsset = charsset + L if 'n' in t: charsset = charsset + N if 's' in t: charsset = charsset + S if 'a' == t: charsset = charsset + U + L + N + S return ''.join(random.choice(charsset) for _ in range(0, int(z))) # GET ARGUMENTS using ARGPARSE parser = argparse.ArgumentParser(description='\n Create a random password\n\ Special characters, numbers, UPPERCASE -"Oscar",\n\ and lowercase -"lima" to avoid confusion.\n\ Default options (no arguments): -c 16 -a\n\ \t\tEnjoy! --0NetEnv@gmail.com', formatter_class=argparse.RawTextHelpFormatter) parser.add_argument("-c", "--count", dest="count", action="store", help="password length") parser.add_argument("-a", "--all", help="same as -l -n -s -u", action="store_true") parser.add_argument("-l", "--lower", help="include lowercase characters", action="store_true") parser.add_argument("-n", "--number", help="include 0-9", action="store_true") parser.add_argument("-s", "--special", help="include special characters", action="store_true") parser.add_argument("-u", "--upper", help="include uppercase characters", action="store_true") parser.add_argument("-p", "--license", help="print license and exit", action="store_true") # COLLECT ARGPARSE RESULTS results = args = parser.parse_args() # CHECK RESULTS # Check that a length was given. # If not, gripe and exit. if args.count == '0': print ("Input error:\nCannot create a zero length password.\nExiting") exit (0) # check character results and add to counter if # selection is made. if args.lower: typo = typo + 'l' counter = counter + 1 #print "lower" if args.number: typo = typo + 'n' counter = counter + 1 #print "number" if args.special: typo = typo + 's' counter = counter + 1 #print "special" if args.upper: typo = typo + 'u' counter = counter + 1 #print "upper" if args.all: typo = 'a' counter = counter + 1 #print "all" if args.license: print (license) exit (1) # CHECK COUNTER # Check our counter and see if we used any command line # options. We don't want to error out. # try it gracefully. If no arguments are given, # use defaults and tell the user. # args.count comes from argparse and by default requires # an input to '-c'. We want to get around that for the # sake of convenience. # Without further adieu, here's our if statement: if args.count: if counter == 0: typo = 'a' print ("defaulting to '--all'") print (line) print (pwgen(results.count,typo)) else: if counter == 0: typo = 'a' print ("defaulting to '--count 16 --all'") print (line) print (pwgen(c,typo)) print (line) #print typo
我喜欢语言学,在我的方法中,我通过交替辅音和元音来创造具有高熵熵的令人难忘的伪字。
- 不容易受字典攻击
- 可以说是令人难忘的好机会
- 与体面的力量短密码
- 可选参数添加一个随机数字的兼容性(难以记忆,但符合旧密码安全思维构build的应用程序,例如需要一个数字)
Python代码:
import random, string def make_pseudo_word(syllables=5, add_number=False): """Alternate random consonants & vowels creating decent memorable passwords """ rnd = random.SystemRandom() s = string.ascii_lowercase vowels = 'aeiou' consonants = ''.join([x for x in s if x not in vowels]) pwd = ''.join([rnd.choice(consonants)+rnd.choice(vowels) for x in 'x'*syllables]).title() if add_number: pwd += str(rnd.choice(range(10))) return pwd >>> make_pseudo_word(syllables=5) 'Bidedatuci' >>> make_pseudo_word(syllables=5) 'Fobumehura' >>> make_pseudo_word(syllables=5) 'Seganiwasi' >>> make_pseudo_word(syllables=4) 'Dokibiqa' >>> make_pseudo_word(syllables=4) 'Lapoxuho' >>> make_pseudo_word(syllables=4) 'Qodepira' >>> make_pseudo_word(syllables=3) 'Minavo' >>> make_pseudo_word(syllables=3) 'Fiqone' >>> make_pseudo_word(syllables=3) 'Wiwohi'
缺点:
- 讲拉丁语和日耳曼语的人以及那些熟悉英语的人
- 一个应该使用与应用程序用户或焦点组和语调为主的语言的元音和辅音
这里是另一个实现(python 2;需要一些小的重写来使它在3中工作)比OJW快得多,尽pipe有相反的意见/暗示,它似乎循环通过词典中的每个词。 OJW脚本在我机器上的时间是80,000 IOP SSD:
real 0m3.264s user 0m1.768s sys 0m1.444s
下面的脚本将整个字典加载到一个列表中,然后根据随机select的索引值select单词,使用OJW的正则expression式进行过滤。
这也产生了10个密码集,允许通过命令行参数来调整单词的数量,并添加数字和符号填充(也是可调整的长度)。
此脚本的示例时间:
real 0m0.289s user 0m0.176s sys 0m0.108s
用法:xkcdpass-mod.py 2 4(例如,这些是默认值)。
它在输出中打印空格以方便阅读,尽pipe我几乎从未遇到过允许使用它们的在线服务,所以我会忽略它们。 这绝对可以用argparse或getopt来清理,并允许开关包含空格或不包括符号,首字母等,还有一些额外的重构,但是我还没有做到这一点。 所以,没有进一步的道理:
#!/usr/bin/env python #Copyright AMH, 2013; dedicated to public domain. import os, re, sys, random from sys import argv def getargs(): if len(argv) == 3: numwords = argv[1] numpads = argv[2] return(numwords, numpads) elif len(argv) == 2: numwords = argv[1] numpads = 4 return (numwords, numpads) else: numwords = 2 numpads = 4 return (numwords, numpads) def dicopen(dictionary="/usr/share/dict/american-english"): f = open(dictionary, "r") dic = f.readlines() return dic def genPassword(numwords, numpads): r = random.SystemRandom() pads = '0123456789!@#$%^&*()' padding = [] words = dicopen() wordlist = [] for i in range (0,int(numpads)): padding.append(pads[r.randint(0,len(pads)-1)]) #initialize counter for only adding filtered words to passphrase j = 0 while (j < int(numwords)): inclusion_criteria = re.compile('^[az]{5,10}$') #Select a random number, then pull the word at that index value, rather than looping through the dictionary for each word current_word = words[r.randint(0,len(words)-1)].strip() #Only append matching words if inclusion_criteria.match(current_word): wordlist.append(current_word) j += 1 else: #Ignore non-matching words pass return(" ".join(wordlist)+' '+''.join(padding)) if(__name__ == "__main__"): for i in range (1,11): print "item "+str(i)+"\n"+genPassword(getargs()[0], getargs()[1])
示例输出:
[✗]─[user@machine]─[~/bin] └──╼ xkcdpass-mod.py item 1 digress basketball )%^) item 2 graves giant &118 item 3 impelled maniacs ^@%1
而要去完整的“正确的马电池钉”(CHBS),没有填充:
┌─[user@machine]─[~/bin] └──╼ xkcdpass-mod.py 4 0 item 1 superseded warred nighthawk rotary item 2 idealize chirruping gabbing vegan item 3 wriggling contestant hiccoughs instanced
根据https://www.grc.com/haystack.htm ,为了所有的实际目的,假设每秒100兆(即100 TH / s)的较短版本将需要大约五千万到六千万个世纪才能破解; 完整的CHBS = 1.24百万亿亿年; 这个数字是15.51万亿亿亿年。
即使征募整个比特币采矿networking(截至撰写本文时为止约2500TH / s),短版本仍然可能需要2.5-3亿年才能打破,这对于大多数目的而言可能足够安全。
实施@Thomas色情解决scheme:(无法评论@Yossi不精确的答案)
import string, os chars = string.letters + string.digits + '+/' assert 256 % len(chars) == 0 # non-biased later modulo PWD_LEN = 16 print ''.join(chars[ord(c) % len(chars)] for c in os.urandom(PWD_LEN))
import uuid print('Your new password is: {0}').format(uuid.uuid4())
你的实现有一些问题:
random.seed = (os.urandom(1024))
这不会给随机数发生器种子; 它用一个stringreplaceseed函数。 你需要调用seed ,像random.seed(…) 。
print ''.join(random.choice(chars) for i in range(length))
Python的默认PRNG是一个Mersenne Twister,它不是一个密码强的PRNG,所以我很谨慎使用它来encryption。 The random module includes random.SystemRandom , which on at least most *nix systems, should use a CSPRNG. 但是 ,
random.choice(chars)
…is implemented as…
def choice(self, seq): """Choose a random element from a non-empty sequence.""" return seq[int(self.random() * len(seq))] # raises IndexError if seq is empty
…in Python 2 . Unfortunately, self.random here is a C function, so this gets hard to see; the code smell here is that this code almost certainly doesn't choose uniformly. The code has completely changed in Python 3, and does a much better job of ensuring uniformity. The Python 3 docs for randrange note,
Changed in version 3.2:
randrange()is more sophisticated about producing equally distributed values. Formerly it used a style likeint(random()*n)which could produce slightly uneven distributions.
randrange and choice both call the same method ( _randbelow ) under the hood.
In Python 3, choice is fine; in Python 2, it only comes close to a uniform distribution, but does not guarantee it. Since this is crypto, I lean on the "take no chances" side of the fence, and would like to have that guarantee.
It is easy 🙂
def codegenerator(): alphabet = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" pw_length = 8 mypw = "" for i in range(pw_length): next_index = random.randrange(len(alphabet)) mypw = mypw + alphabet[next_index] return mypw
and the do:
print codegenerator()
Thanks http://xkcd.com/936/
A little bit off topic, but I made this, using also TKinter. Hope it can helps:
import os, random, string from tkinter import * def createPwd(): try: length = int(e1.get()) except ValueError: return chars = string.ascii_letters + string.digits + '!@#$%^&*()?\/' random.seed = (os.urandom(1024)) e2.config(state=NORMAL) e2.delete(0,'end') e2.insert(0,''.join(random.choice(chars) for i in range(length))) e2.config(state="readonly") mainWindow = Tk() mainWindow.title('Password generator') mainWindow.resizable(0,0) f0 = Frame(mainWindow) f0.pack(side=TOP,pady=5,padx=5,fill=X,expand=1) Label(f0,text="Length: ",anchor=E).grid(row=0,column=0,sticky=E) e1 = Entry(f0) e1.insert(0,'12') e1.grid(row=0,column=1) btn = Button(f0,text="Generate") btn['command'] = lambda: createPwd() btn.grid(row=0,column=2,rowspan=1,padx=10,ipadx=10) Label(f0,text="Generated password: ",anchor=E).grid(row=1,column=0,sticky=E) e2 = Entry(f0) e2.grid(row=1,column=1) createPwd() #starting main window mainWindow.mainloop()
This is a simple small program addressed to people whome can't figure out a secure passwords for there own public accounts.
Just run the program on a command console and pass in a bunch of letters that seems familiar to you, and it will generate a sequence of symbols based on what you've inserted.
of course, the program does not support multiple sequences generation.
You can download the code from my github pull: https://github.com/abdechahidely/python_password_generator
from string import ascii_lowercase, ascii_uppercase, digits, punctuation from random import randint, choice, shuffle from math import ceil from re import finditer lower_cases = ascii_lowercase upper_cases = ascii_uppercase lower_upper = dict(zip(lower_cases, upper_cases)) upper_lower = dict(zip(upper_cases, lower_cases)) punctuations = '#$%&@!?.' space = ' ' class PunctOrDigit(): def __init__(self, number_of_punctuations, number_of_digits): self.puncts = number_of_punctuations self.digits = number_of_digits self.dupl_puncts = self.puncts self.dupl_digits = self.digits def PorD(self): symbol_type = choice('pd') if symbol_type == 'p': if self.puncts == 0: return 'd' else: self.puncts -= 1 return symbol_type if symbol_type == 'd': if self.digits == 0: return 'p' else: self.digits -= 1 return symbol_type def reset(self): self.puncts = self.dupl_puncts self.digits = self.dupl_digits def is_empty(text): for symbol in text: if symbol != space: return False return True def contain_unauthorized_symbols(text): for symbol in text: if symbol in punctuation or symbol in digits: return True return False def user_input(): user_input = input('-- Sentence to transform: ') while is_empty(user_input) or len(user_input) < 8 or contain_unauthorized_symbols(user_input): user_input = input('-- Sentence to transform: ') return user_input def number_of_punctuations(text): return ceil(len(text) / 2) - 3 def number_of_digits(text): return ceil(len(text) / 2) - 2 def total_symbols(text): return (number_of_digits(text) + number_of_punctuations(text), number_of_punctuations(text), number_of_digits(text)) def positions_to_change(text): pos_objct = PunctOrDigit(number_of_punctuations(text), number_of_digits(text)) positions = {} while len(positions) < total_symbols(text)[0]: i = randint(0,len(text)-1) while i in positions: i = randint(0,len(text)-1) positions[i] = pos_objct.PorD() pos_objct.reset() return positions def random_switch(letter): if letter in lower_cases: switch_or_pass = choice('sp') if switch_or_pass == 's': return lower_upper[letter] else: return letter if letter in upper_cases: switch_or_pass = choice('sp') if switch_or_pass == 's': return upper_lower[letter] else: return letter def repeated(text): reps = {} for letter in set(list(text)): indexs = [w.start() for w in finditer(letter, text)] if letter != ' ': if len(indexs) != 1: reps[letter] = indexs return reps def not_repeated(text): reps = {} for letter in set(list(text)): indexs = [w.start() for w in finditer(letter, text)] if letter != ' ': if len(indexs) == 1: reps[letter] = indexs return reps def generator(text, positions_to_change): rep = repeated(text) not_rep = not_repeated(text) text = list(text) for x in text: x_pos = text.index(x) if x not in positions_to_change: text[x_pos] = random_switch(x) for x in rep: for pos in rep[x]: if pos in positions_to_change: if positions_to_change[pos] == 'p': shuffle(list(punctuations)) text[pos] = choice(punctuations) if positions_to_change[pos] == 'd': shuffle(list(digits)) text[pos] = choice(digits) for x in not_rep: for pos in not_rep[x]: if pos in positions_to_change: if positions_to_change[pos] == 'p': shuffle(list(punctuations)) text[pos] = choice(punctuations) if positions_to_change[pos] == 'd': shuffle(list(digits)) text[pos] = choice(digits) text = ''.join(text) return text if __name__ == '__main__': x = user_input() print(generator(x, positions_to_change(x)))
Here is my random password generator after researching this topic:
`import os, random, string #Generate Random Password UPP = random.SystemRandom().choice(string.ascii_uppercase) LOW1 = random.SystemRandom().choice(string.ascii_lowercase) LOW2 = random.SystemRandom().choice(string.ascii_lowercase) LOW3 = random.SystemRandom().choice(string.ascii_lowercase) DIG1 = random.SystemRandom().choice(string.digits) DIG2 = random.SystemRandom().choice(string.digits) DIG3 = random.SystemRandom().choice(string.digits) SPEC = random.SystemRandom().choice('!@#$%^&*()') PWD = None PWD = UPP + LOW1 + LOW2 + LOW3 + DIG1 + DIG2 + DIG3 + SPEC PWD = ''.join(random.sample(PWD,len(PWD))) print(PWD)`
This will generate a random password with 1 random uppercase letter, 3 random lowercase letters, 3 random digits, and 1 random special character–this can be adjusted as needed. Then it combines each random character and creates a random order. I don't know if this is considered "high quality", but it gets the job done.
Base64 let us encode binary data in a human readable/writable mode with no data loss.
import os random_bytes=os.urandom(12) secret=random_bytes.encode("base64")
This is more for fun than anything. Scores favorably in passwordmeter.com but impossible to remember.
#!/usr/bin/ruby puts (33..126).map{|x| ('a'..'z').include?(x.chr.downcase) ? (0..9).to_a.shuffle[0].to_s + x.chr : x.chr}.uniq.shuffle[0..41].join[0..41]
