如何使用众包sorting来排列一百万张图片
我想通过制作一个游戏来让网站访问者对它们进行评价,以便找出哪些人们觉得最吸引人的图像,从而排列一系列的风景图像。
什么将是一个很好的方法呢?
- 热或不风格 ? 即显示单个图像,请求用户从1-10进行排名。 正如我所看到的,这允许我平均分数,而且我只需要确保在所有图像上得到均匀分配的选票。 相当简单的实施。
- 选A或B ? 即显示两个图像,要求用户select更好的一个。 这是有吸引力的,因为没有数字排名,这只是一个比较。 但是,我将如何执行它? 我的第一个想法是做一个快速sorting,比较操作是由人类提供的,一旦完成,只需重复无穷无尽的sorting。
你会怎么做?
如果你需要数字,我在每天有20000次访问的网站上谈论一百万张图片。 我想可能有一小部分人可能为了争吵而玩这个游戏,可以说我每天可以产生2000人的sorting操作! 这是一个非盈利的网站,最终的好奇将通过我的个人资料find它:)
正如其他人所说,排名第一到第十位并不那么好,因为人们有不同的层次。
Pick A或B方法的问题在于它不能保证系统是传递的(A可以击败B,但B击败C,C击败A)。 具有非传递性比较运算符会破坏sortingalgorithm 。 用这个快速sorting,对于这个例子,没有被选为主键的字母将被错误地排列在一起。
在任何时候,你都需要对所有图片进行绝对排名(即使其中的一些/全部都是并列的)。 你也希望你的排名不会改变, 除非有人投票 。
我会使用Pick A或B(或tie)方法,但要确定排名类似于Elo评分系统的排名,这个评分系统用于2人游戏(原来是国际象棋)的排名:
Elo球员评分系统将球员的比赛logging与对手的比赛logging进行比较,并确定球员赢得比赛的概率。 这个概率因素决定了根据每场比赛的结果,球员的等级上升或下降的点数。 当一个玩家击败一个拥有较高等级的对手时,玩家的等级会比打败一个等级较低的玩家更高(因为玩家应该击败那些拥有较低等级的对手)。
Elo系统:
- 所有新玩家的基础评分为1600
- WinProbability = 1 /(10 ^((对手的当前评分 – 玩家目前评分)/ 400)+ 1)
- 如果他们赢了比赛,得分= 1分,如果输了,得0分,平局0.5。
- 球员的新评级=球员的旧评级+(K值*(得分球员的赢球概率))
用图片replace“球员”,你有一个简单的方法来调整两个图片的评分基于公式。 然后,您可以使用这些数字分数执行排名。 (K值为锦标赛的“等级”,小本地锦标赛为8-16,大型邀请赛/地区锦标赛为24-32,您可以使用像20)这样的常数。
使用这种方法,您只需要为每个图片保留一个数字,比每个图片的每个图层保留在另一个图片上要less得多。
编辑:根据评论添加更多的肉。
对这个问题最天真的方法有一些严重的问题。 最糟糕的是bash.org和qdb.us如何显示报价 – 用户可以向上(+1)或向下(-1)投票报价,而最佳报价列表则按净总得分sorting。 这有一个可怕的时间偏差 – 旧的报价已经积累了大量的正面投票通过简单的长寿,即使他们只是轻微的幽默。 如果笑话随着年龄的增长变得更有趣的话,这个algorithm也许会有意义,但是 – 相信我 – 他们不会。
有各种各样的尝试来解决这个问题 – 看每个时间段的正面投票数量,加权最近的投票,对较老的投票执行衰减系统,计算正面和反面投票的比率等。大多数遭受其他缺点。
最好的解决scheme – 我认为 – 是最有趣 的最可爱 , 最公平 , 最好用的网站 – 修改后的Condorcet投票系统 :
系统根据每个人所面临的事情给出每个人的数量,他们通常会打出多less百分比。 所以每个人得到百分比NumberOfThingsIBeat /(NumberOfThingsIBeat + NumberOfThingsThatBeatMe)。 而且,直到他们与合理的百分比进行比较之后,这些东西才被排除在首位。
如果有一个Condorcet赢家,这个方法会find它。 由于这是不太可能的,鉴于统计性质,它find了一个“最接近”作为Condorcet获胜者。
有关实现这些系统的更多信息,维基百科对排名对的页面应该是有帮助的。
algorithm要求人们比较两个对象(你的Pick-A-or-B选项),但坦率地说,这是一件好事。 我相信,在决策理论中,人们在比较两个对象时比在抽象的等级上更好。 数百万年的进化使我们善于从树上摘下最好的苹果,但却很难决定我们select的苹果如何密切地依赖于真正的柏拉图式苹果。 (顺便说一句,这就是为什么层次分析法是如此的漂亮……但是这有点偏离主题。)
最后要指出的是,SO使用一种algorithm来find与bash.org的algorithm非常相似的最佳答案,以find最好的报价。 它在这里运行得很好,但是在那里很糟糕 – 很大程度上是因为一个旧的,高度评价的但现在过时的答案很可能会被编辑。 bash.org不允许编辑,现在还不清楚,即使你可以编辑十年前关于现在的互联网模因的笑话,你甚至不知道该怎么做。无论如何,我的观点是正确的algorithm通常取决于你的问题的细节。 🙂
我知道这个问题是相当古老,但我想我会贡献
我会看看微软研究院开发的TrueSkill系统。 这就像ELO一样,但收敛时间要快得多(与线性相比看起来是指数级的),所以你可以从每个投票中获得更多的收益。 然而,从math上来说这更复杂。
我不喜欢“ 热门”风格 。 不同的人会select不同的数字,即使他们都喜欢图像完全一样。 另外我讨厌评分10分,我不知道select哪个号码。
选A或B要简单得多。 您可以看到两个图像,并在网站上的图像之间进行比较。
维基百科的这些方程式使计算Elo评分变得更简单/更有效,图像A和B的algorithm将变得简单:
- 从数据库中获取Ne,mA,mB和等级RA,RB。
- 使用执行的比较次数(Ne)和图像比较次数(m)和电stream额定值计算KA,KB,QA,QB:


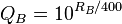
- 计算EA和EB。


- 得分胜者S:胜者1,失败者0,如果你有平局0.5,
-
计算两个使用的新评级:
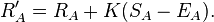
-
更新数据库中的新评级RA,RB并计算mA,mB。
你可能想要一个组合。
第一阶段:热或不风格(尽pipe我会select3选项:吮吸,哦/好吧,酷!)
一旦你把这个组合分成3个桶,那么我会从同一个桶中select两个图像,然后select“哪个更好”
然后,您可以使用英式足球的升级和降级系统将顶级的“吮吸”移动到Meh / OK区域,以改善边缘情况。
排名1-10不会工作,每个人都有不同的水平。 总是给3-7评分的人会让他的排名黯然失色。
a或b更可行。
哇,我迟到了。
我非常喜欢ELO系统,但是就像欧文说的那样,在我看来,你会慢慢build立任何重要的结果。
我相信人类比仅仅比较两幅图像有更大的能力,但是你想保持相互作用的最低限度。
那么你如何显示n张图像(n是你可以在屏幕上显示的任何数字,这可能是10,20,30,这取决于用户的偏好),并让他们select他们认为最好的那个。 现在回到ELO。 你需要修改你的评分系统,但保持同样的精神。 事实上,你将一个图像与n-1个图像进行比较。 所以你做ELO等级n-1次,但你应该把等级的变化除以n-1来匹配(这样n的不同值的结果是相互一致的)。
你完成了。 你现在已经得到了世界上最好的。 点击一个简单的评级系统,处理许多图像。
如果您更喜欢使用selectA或B策略,我会推荐这篇文章: http : //research.microsoft.com/en-us/um/people/horvitz/crowd_pairwise.pdf
Chen,X.,Bennett,PN,Collins-Thompson,K.和Horvitz,E.(2013年2月)。 在众包的环境中成对的排名聚合。 在第六届ACM国际networkingsearch和数据挖掘会议论文集(第193-202页)中。 ACM。
本文介绍了将着名的Bradley-Terry两两比较模型扩展到众包设置的Crowd-BT模型。 它还提供了一个自适应学习algorithm来提高模型的时间和空间效率。 你可以在Github上find这个algorithm的matlab实现(但是我不知道它是否工作)。
不存在的网站whatsbetter.com使用了Elo风格的方法 。 您可以在Internet Archive上的FAQ中阅读这个方法。
挑A或B是最简单和不太容易产生偏见的,然而在每次人际互动时,它都会给你提供大量的信息。 我认为,由于偏见减less,皮克是优越的,并在极限,它提供了相同的信息。
一个非常简单的评分scheme是每张照片都有一个计数。 当某人给出一个正的比较增量计数,当有人给出一个负面的比较时,减less计数。
sorting一个一百万的整数列表非常快,在现代计算机上花费不到一秒钟的时间。
这就是说,这个问题是相当不合适的 – 这将需要你50天,每个图像只显示一次。
我敢打赌,尽pipe你对排名最高的图像更感兴趣? 所以,您可能希望按照预测排名偏好您的图像检索 – 所以您更可能显示已经实现了一些正面比较的图像。 这样你就可以更快地开始显示“有趣”的图像。
我喜欢快速sorting选项,但我会做一些微调:
- 将“比较”结果保留在数据库中,然后对其进行平均。
- 通过给用户4-6个图像并对它们进行sorting,获得每个视图的多个比较。
- select要显示的图像,通过运行qsort并logging和修剪任何你没有足够数据的东西。 然后当你有足够的项目logging,吐出一页。
另一个有趣的select是使用人群来教一个neural network。
