Solr与ElasticSearch
这些技术之间的核心架构差异是什么?
另外,什么用例通常更适合每个?
更新
现在问题范围已经得到纠正,我也可以在这方面补充一些:
Apache Solr和ElasticSearch之间有许多比较,所以我会引用那些我发现最有用的东西,即覆盖最重要的方面:
-
Bob Yoplait已经将Kimchy的答案与ElasticSearch,Sphinx,Lucene,Solr,Xapian联系了起来。 哪个适合哪种用法? ,他总结了他为什么继续创buildElasticSearch的原因,他认为与Solr相比,他提供了一个更优越的分布式模型和易用性 。
-
Ryan Sonnek的实时search:Solr与Elasticsearch提供了深入分析/比较,并解释了为什么他从Solr切换到ElasticSeach,尽pipe他已经是一个快乐的Solr用户 – 他总结如下:
Solr可能是构build标准search应用程序时的首选武器,但Elasticsearch通过创build现代实时search应用程序的架构将其提升到了一个新的水平。 渗stream是一个激动人心的创新function,单手将Solr从水中吹出。 Elasticsearch是可扩展的,快速的,是一个集成的梦想 。 Adios Solr,很高兴认识你。 [强调我的]
-
维基百科关于ElasticSearch的文章引用了德国知名iX杂志的一个比较 ,列举了优点和缺点,这几乎总结了上面已经说过的内容:
优点 :
- ElasticSearch是分布式的。 不需要单独的项目。 副本也接近实时,这就是所谓的“推复制”。
- ElasticSearch完全支持Apache Lucene的近实时search。
- 处理多租户并不是一个特殊的configuration,使用Solr更高级的设置是必要的。
- ElasticSearch引入了网关的概念,使整个备份更容易。
缺点 :
-
只有一个主要开发者[根据当前的elasticsearch GitHub组织不再适用,除了首先有一个非常活跃的提交者基础] -
没有autowarmingfunction[根据新的索引预热API不再适用]
初始答案
它们是针对完全不同用例的完全不同的技术,因此无法用任何有意义的方式进行比较:
-
Apache Solr – Apache Solr为Lucene提供了一个易于使用的快速search服务器 ,其function包括分面,可扩展性等等
-
Amazon ElastiCache – Amazon ElastiCache是一项Web服务,可以轻松部署,操作和扩展云中的内存caching 。
- 请注意, Amazon ElastiCache与广泛采用的内存对象caching系统Memcached是协议兼容的,因此您现在使用的现有Memcached环境中的代码,应用程序和常用工具将与该服务无缝 协作 (请参阅Memcached了解详细信息)。
[强调我的]
也许这种方式与以下两种相关的技术混淆了:
-
ElasticSearch – 它是一个build立在Apache Lucene之上的开源(Apache 2)分布式RESTfulsearch引擎。
-
Amazon CloudSearch – Amazon CloudSearch是云中的完全托pipesearch服务,允许客户轻松地将快速和高度可扩展的searchfunction集成到其应用程序中。
Solr和ElasticSearch产品乍一看听起来非常相似,都使用相同的后端search引擎,即Apache Lucene 。
虽然Solr较为老旧,function相当多,成熟度也相应得到了广泛的应用,但ElasticSearch专门用于解决Solr在现代云环境中存在的可扩展性要求的缺点,而这些缺点很难用Solr解决 。
因此,将ElasticSearch与最近推出的Amazon CloudSearch进行比较可能是最有用的(参见开始在一个小时内开始search的价格低于$ 100 /月 ),因为这两个原则都声称覆盖相同的用例。
我看到上面的一些答案现在有点过时了。 从我的angular度来看,我每天都同时使用Solr(Cloud和非Cloud)和ElasticSearch,这里有一些有趣的区别:
- 社区:Solr拥有更大,更成熟的用户,开发者和贡献者社区。 ES拥有一个规模较小,但活跃的用户社区和不断增长的贡献者社区
- 成熟度:Solr更成熟,但ES增长迅速,我认为它是稳定的
- performance:很难判断。 我/我们没有做直接的性能基准。 LinkedIn的一位员工曾经比较过Solr和ES与Sensei,但最初的结果应该被忽略,因为他们对Solr和ES都使用了非专家级的设置。
- devise:人们喜欢Solr。 Java API有些冗长,但人们喜欢它是如何放在一起的。 Solr代码不幸的不总是很漂亮。 另外,ES内置了分片,实时复制,文档和路由。 Solr也存在这样的一些情况,这有点像后想。
- 支持:有些公司为Solr和ElasticSearch提供技术和咨询支持。 我认为唯一提供支持的公司是Sematext(披露:我是Sematext创始人)
- 可扩展性:两者都可以扩展到非常大的集群。 ES比Solr之前的Solr 4.0版本更容易扩展,但Solr 4.0不再是这种情况。
有关Solr与ElasticSearch主题更全面的介绍,请参阅http://blog.sematext.com/2012/08/23/solr-vs-elasticsearch-part-1-overview/ 。 这是Sematext系列文章中直接和中立的Solr与ElasticSearch比较的第一篇文章。 披露:我在Sematext工作。
我发现很多人在这方面的function和function方面都回答了这个ElasticSearch和Solr的问题,但是在这里(或其他地方)我们没有看到他们在性能方面的比较。
这就是为什么我决定进行自己的调查 。 我把一个已经编码的异构数据源微服务用于术语search。 我将Solr换成了ElasticSearch,然后我在AWS上运行了一个已经编码的负载testing应用程序,并捕获了后续分析的性能指标。
这是我发现的。 索引文件时,ElasticSearch的吞吐量提高了13%,但Solr的速度提高了十倍。 当查询文档时,Solr的吞吐量增加了五倍,比ElasticSearch快了五倍。
我一直在为.Net应用程序的solr和elasticsearch工作。 我面临的主要区别是
弹性search:
- 更多的代码和更less的configuration,但是有api的改变,但仍然是一个代码的变化
- 对于复杂types,在types内embeddedtypes即嵌套types(不能在solr中实现)
Solr:
- 代码less,configuration多,维护量less
- 在查询过程中对结果进行分组(大量工作要做到在弹性search中不能直接实现)
由于Apache Solr的悠久历史,我认为Solr的一个优势是其生态系统 。 有许多Solr插件用于不同types的数据和目的。
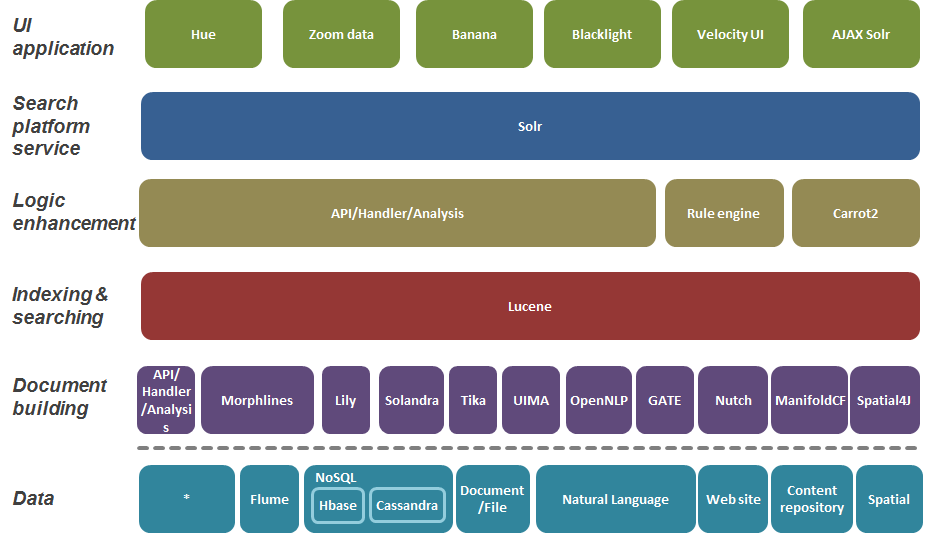
search平台从下到上的层次从下到上:
- 数据
- 目的:表示各种数据types和来源
- 文件build设
- 目的:为索引build立文档信息
- 索引和search
- 目的:构build和查询文档索引
- 逻辑增强
- 目的:处理search查询和结果的附加逻辑
- search平台服务
- 目的:添加search引擎核心的附加function以提供服务平台。
- UI应用程序
- 目的:最终用户search界面或应用程序
参考文章: 企业search
我创build了一个弹性search和Solr和splunk之间的主要区别表,你可以使用它作为2016年更新: 
虽然以上所有链接都有优点,过去也让我受益匪浅,但作为一名在过去15年中“接触过各种Lucenesearch引擎”的语言专家,我不得不说Python的弹性search开发速度非常快。 这就是说,一些代码感觉不直观。 所以,我从开源的angular度向ELK协议栈Kibana的一个组件发展,并发现我可以很容易地在Kibana中生成一些有点神秘的elasticsearch代码。 另外,我也可以把Chrome Sense es的查询转换成Kibana。 如果您使用Kibana评估ES,它将进一步加快您的评估速度。 在其他平台上花费数小时才能在Sense上以弹性search(RESTful界面)的forms运行在最后几分钟(最大数据集)的Sense中; 在几秒钟内最好。 弹性search的文档,而700多页,没有回答我通常会在SOLR或其他Lucene文档中解决的问题,这显然需要更多的时间来分析。 此外,你可能想看看在弹性search聚合,已经采取了一个新的水平。
更大的图片:如果您正在从事数据科学,文本分析或计算语言学研究,那么elasticsearch就会在信息检索领域拥有一些似乎具有创新性的排名algorithm。 如果您正在使用任何TF / IDFalgorithm,文本频率/逆文档频率,elasticsearch将这一1960年代的algorithm扩展到一个新的水平,即使使用BM25,最佳匹配25和其他相关sortingalgorithm。 因此,如果您在评分或排列单词,短语或句子时,elasticsearch可以即时进行评分,而不需要花费数小时的其他数据分析方法的大量开销,这又是一个节省的弹性search时间。 使用es,将汇总中的一些优势与实时JSON数据相关性评分和排名相结合,您可以根据敏捷(故事)或架构(用例)方法find一个成功的组合。
注意:上面看到了关于聚合的类似讨论,但是没有聚合和相关性评分 – 我对任何重叠的道歉。 披露:我不会为弹性工作,因为不同的架构path,他们不可能在短期内从他们出色的工作中受益,除非我使用elasticsearch做一些慈善工作,这不是一个坏主意
我已经使用Elasticsearch 3年和Solr大约一个月,我觉得与Solr安装相比,elasticsearch集群相当容易安装。 Elasticsearch有一个很好的解释帮助文件库。 其中一个使用案例是在ES中提供的Histogram Aggregation,但在Solr中找不到。
如果您已经在使用SOLR,请继续遵守。 如果您正在启动,请进行弹性search。
SOLR最大的问题已经解决,已经相当成熟。
我只使用Elastic-search。 因为我发现solr很难开始。 弹性searchfunction:
- 易于启动,设置很less。 即使是新手也可以一步步设置群集。
- 使用NoSQL查询的简单Restful API。 许多语言库可以方便访问。
- 好文件,你可以阅读这本书:。 在官方网站上有一个网页版本。
在solr中添加一个嵌套的文档非常复杂,嵌套的数据search也非常复杂。 但Elastic Search易于添加嵌套的文档和search
